初次學習Tensorflow最困難的地方莫過於不知道從何下手,已經學會很多的Deep Learning理論,但是要自己使用Tensorflow將Network建起來卻是非常困難的,這篇文章我會先簡單的介紹幾個Tensorflow的概念,最後利用這些概念建立一個簡單的分類模型。
本單元程式碼可於Github下載。
首先,先import一些會用到的function
| import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
tf.logging.set_verbosity(tf.logging.ERROR)
# Config the matplotlib backend as plotting inline in IPython
%matplotlib inline
|
MNIST Dataset
定義summary function以便於觀察ndarray。
| def summary(ndarr):
print(ndarr)
print('* shape: {}'.format(ndarr.shape))
print('* min: {}'.format(np.min(ndarr)))
print('* max: {}'.format(np.max(ndarr)))
print('* avg: {}'.format(np.mean(ndarr)))
print('* std: {}'.format(np.std(ndarr)))
print('* unique: {}'.format(np.unique(ndarr)))
|
ndarray是numpy的基本元素,它非常便於我們做矩陣的運算。
我們使用MNIST Dataset來當作我們練習的標的,MNIST包含一包手寫數字的圖片,每張圖片大小為28x28,每一張圖片都是一個手寫的阿拉伯數字包含0到9,並且標記上它所對應的數字。我們的目標就是要利用MNIST做到手寫數字辨識。
在Tensorflow你可以很簡單的得到「處理過後的」MNIST,只要利用以下程式碼,
| from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data/', one_hot=True)
train_data = mnist.train
valid_data = mnist.validation
test_data = mnist.test
|
| Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes.
Extracting MNIST_data/train-images-idx3-ubyte.gz
Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes.
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes.
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes.
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
|
每個train_data、valid_data、test_data都包含兩部分:圖片和標籤。
我們來看一下圖片的部分,train_data.images一共有55000張圖,每一張圖原本大小是28x28,不過特別注意這裡的Data已經先做過預先處理了,因此圖片已經被打平成28x28=784的一維矩陣了,另外每個Pixel的值也先做過「Normalization」了,通常會這樣處理,每個值減去128再除以128,所以你可以從以下的summary中看到它的最大最小值落在0到1之間,還有這個Dataset也已經做過亂數重排了。
| summary(train_data.images)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55 | [[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
...
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]]
* shape: (55000, 784)
* min: 0.0
* max: 1.0
* avg: 0.13070042431354523
* std: 0.30815958976745605
* unique: [0. 0.00392157 0.00784314 0.01176471 0.01568628 0.01960784
0.02352941 0.02745098 0.03137255 0.03529412 0.03921569 0.04313726
0.04705883 0.0509804 0.05490196 0.05882353 0.0627451 0.06666667
0.07058824 0.07450981 0.07843138 0.08235294 0.08627451 0.09019608
0.09411766 0.09803922 0.10196079 0.10588236 0.10980393 0.1137255
0.11764707 0.12156864 0.1254902 0.12941177 0.13333334 0.13725491
0.14117648 0.14509805 0.14901961 0.15294118 0.15686275 0.16078432
0.16470589 0.16862746 0.17254902 0.1764706 0.18039216 0.18431373
0.18823531 0.19215688 0.19607845 0.20000002 0.20392159 0.20784315
0.21176472 0.21568629 0.21960786 0.22352943 0.227451 0.23137257
0.23529413 0.2392157 0.24313727 0.24705884 0.2509804 0.25490198
0.25882354 0.2627451 0.26666668 0.27058825 0.27450982 0.2784314
0.28235295 0.28627452 0.2901961 0.29411766 0.29803923 0.3019608
0.30588236 0.30980393 0.3137255 0.31764707 0.32156864 0.3254902
0.32941177 0.33333334 0.3372549 0.34117648 0.34509805 0.34901962
0.3529412 0.35686275 0.36078432 0.3647059 0.36862746 0.37254903
0.37647063 0.3803922 0.38431376 0.38823533 0.3921569 0.39607847
0.40000004 0.4039216 0.40784317 0.41176474 0.4156863 0.41960788
0.42352945 0.427451 0.43137258 0.43529415 0.43921572 0.4431373
0.44705886 0.45098042 0.454902 0.45882356 0.46274513 0.4666667
0.47058827 0.47450984 0.4784314 0.48235297 0.48627454 0.4901961
0.49411768 0.49803925 0.5019608 0.5058824 0.50980395 0.5137255
0.5176471 0.52156866 0.5254902 0.5294118 0.53333336 0.5372549
0.5411765 0.54509807 0.54901963 0.5529412 0.5568628 0.56078434
0.5647059 0.5686275 0.57254905 0.5764706 0.5803922 0.58431375
0.5882353 0.5921569 0.59607846 0.6 0.6039216 0.60784316
0.6117647 0.6156863 0.61960787 0.62352943 0.627451 0.6313726
0.63529414 0.6392157 0.6431373 0.64705884 0.6509804 0.654902
0.65882355 0.6627451 0.6666667 0.67058825 0.6745098 0.6784314
0.68235296 0.6862745 0.6901961 0.69411767 0.69803923 0.7019608
0.7058824 0.70980394 0.7137255 0.7176471 0.72156864 0.7254902
0.7294118 0.73333335 0.7372549 0.7411765 0.74509805 0.7490196
0.75294125 0.7568628 0.7607844 0.76470596 0.7686275 0.7725491
0.77647066 0.7803922 0.7843138 0.78823537 0.79215693 0.7960785
0.8000001 0.80392164 0.8078432 0.8117648 0.81568635 0.8196079
0.8235295 0.82745105 0.8313726 0.8352942 0.83921576 0.8431373
0.8470589 0.85098046 0.854902 0.8588236 0.86274517 0.86666673
0.8705883 0.8745099 0.87843144 0.882353 0.8862746 0.89019614
0.8941177 0.8980393 0.90196085 0.9058824 0.909804 0.91372555
0.9176471 0.9215687 0.92549026 0.9294118 0.9333334 0.93725497
0.94117653 0.9450981 0.9490197 0.95294124 0.9568628 0.9607844
0.96470594 0.9686275 0.9725491 0.97647065 0.9803922 0.9843138
0.98823535 0.9921569 0.9960785 1. ]
|
來試著畫圖來看看,我們使用ndarray的index功能來選出第10張圖片,train_data.images[10,:]表示的是選第一軸的第10個和第二軸的全部。
| def plot_fatten_img(ndarr):
img = ndarr.copy()
img.shape = (28,28)
plt.imshow(img, cmap='gray')
plt.show()
|
| plot_fatten_img(train_data.images[10,:])
|

很顯而易見的,這是一個0。
接下來來看標籤的部分,train_data.labels不意外的一樣的也是有相應的55000筆資料,所對應的就是前面的每一張圖片,總共有10種類型:0到9,所以大小為(55000, 10)。
| summary(train_data.labels)
|
1
2
3
4
5
6
7
8
9
10
11
12
13 | [[0. 0. 0. ... 1. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
...
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 1. 0.]]
* shape: (55000, 10)
* min: 0.0
* max: 1.0
* avg: 0.1
* std: 0.30000000000000004
* unique: [0. 1.]
|
所以我們來看看上面那張圖片的標籤,
| print(train_data.labels[10])
|
| [1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
|
看起來的確沒錯,在0的位置標示1.,而其他地方標示為0.,因此這是一個標示為0的label沒有錯,這種表示方法稱為One-Hot Encoding,它具有機率的涵義,所代表的是有100%的機會落在0的類別上。
Softmax
通常One-Hot Encoding會搭配Softmax一同服用,最後的Output結果如果是機率分布,那我也需要讓我的Neurel Network可以輸出機率分布。
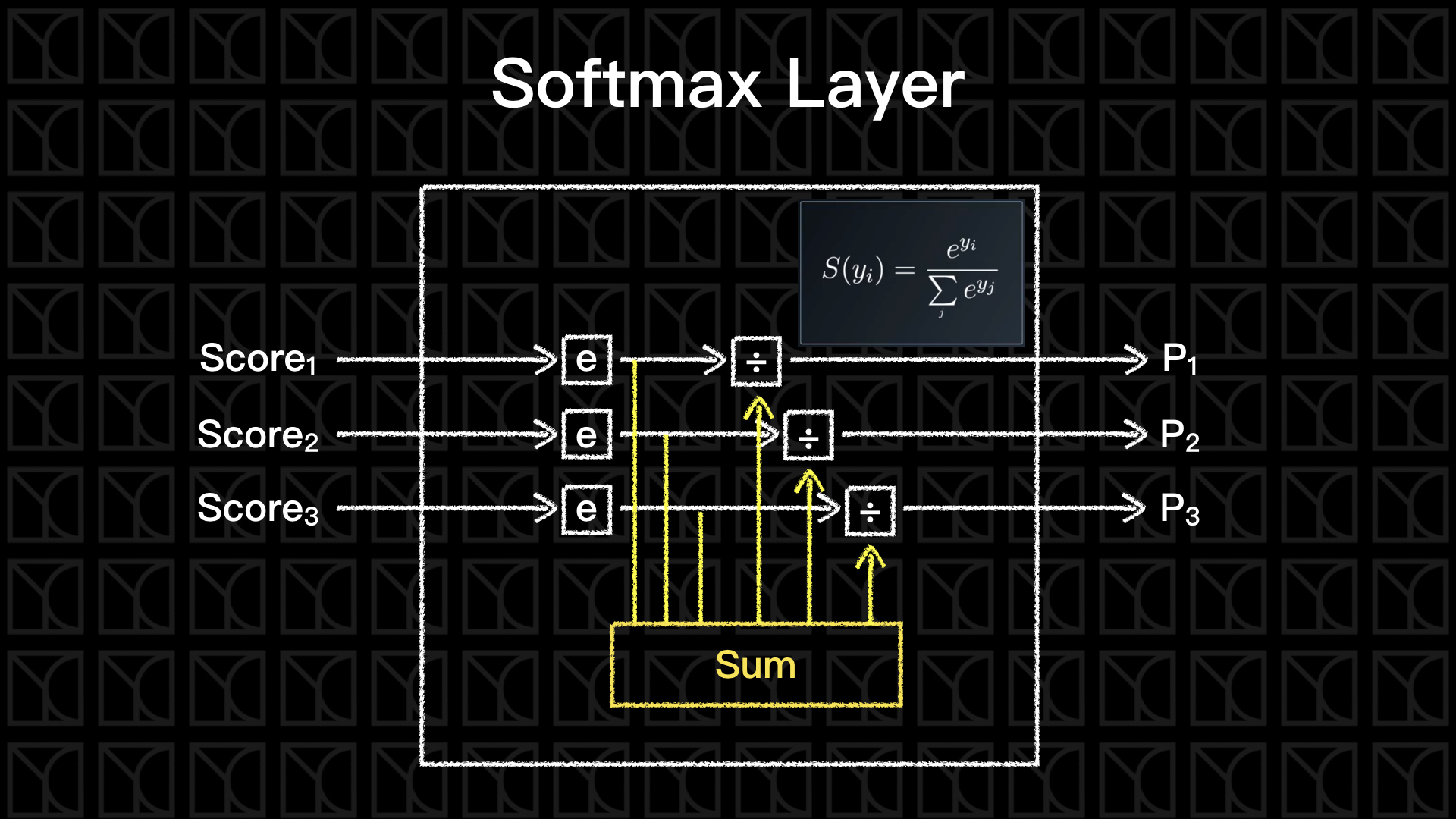
通過Softmax這一層,我們就可以將輸出轉變為以「機率」表示。
我們可以來手刻一個Softmax Function,不過直接套用Tensorflow中函數的也是可以的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | import numpy as np
def softmax(x):
# avoid exp function go to too large,
# pre-reduce before applying exp function
max_score = np.max(x, axis=0)
x = x - max_score
exp_s = np.exp(x)
sum_exp_s = np.sum(exp_s, axis=0)
softmax = exp_s / sum_exp_s
return softmax
scores = [3.0, 1.0, 0.2]
print(softmax(scores))
|
| [0.8360188 0.11314284 0.05083836]
|
Cross-Entropy Loss
一旦我們要處理機率預測的問題,就不可以使用單純的「平方誤差」,而必須使用Cross-Entropy Loss,是這樣計算的:
$$
Loss_{cross-entropy} = - \sum_i y_i ln(s_i)
$$
其中,\(y_i\)為目標Label,\(s_i\)為經過Softmax產生的預測值。
至於如果你想要了解為何需要使用Cross-Entropy Loss?這我在機器學習基石的筆記中已經有提及過,請看介紹Logistic Regression的部分。
分離數據的重要性
在MNIST Dataset中,你會發現分為Training Dataset、Validation Dataset和Testing Dataset,這樣的作法在Machine Learning中是常見且必要的。
流程是這樣的,我們會先使用Training Dataset來訓練Model,並且使用Validation Dataset來檢驗Model的好壞,我們會依據Validation Dataset的檢驗調整Model上的參數,試著盡可能的壓低Validation Dataset的Error,記住!在過程中所產生的所有Models都要保留下來,因為最後選擇的Model並不是Validation Dataset的Error最小的,而是要再由Testing Dataset來做最後的挑選,挑選出能使Testing Dataset的Error最小的Model。
這所有的作法都是為了避免Overfitting的情況發生,也就是機器可能因為看過一筆Data,結果就把這筆Data給完整記了起來,而Data本身含有雜訊,雜訊就這樣滲透到Model裡,確實做到分離是很重要的,讓Model在測試階段時可以使用沒有看過的Data。
因此,Validation Dataset的分離是為了避免讓Model在Training階段看到要驗證的資料,所以更能正確的評估Model的好壞。但這樣是不夠的,人為會根據Validation Dataset來調整Model,這樣無形之中已經將Validation Dataset的資訊間接的經由人傳給了Model,所以還是沒有徹底分離,因此在最後挑選Models時,我們會使用另外一筆從沒看過的資料Testing Dataset來做挑選,一旦挑選完就不能再去調整任何參數了。
Tensorflow工作流程
我們這一篇將會使用Tensorflow實作最簡單的單層Neurel Network,在這之前我們來看看Tensorflow是如何運作的?
深度學習是由一層一層可以微分的神經元所連接而成,數學上可以表示為張量(Tensor)的表示式,我們一般講的矩陣運算是指2x2的矩陣運算,而張量(Tensor)則是拓寬到n維陣列做計算,在Machine Learning當中我們常常需要處理到相當高維度的計算,例如:有五張28x28的彩色圖的表示就必須使用到四維張量,第一維表示第幾張、第二、三維表示圖片的大小、第四維則表示RGB,如果你是物理系的學生應該也對張量不陌生,廣義相對論裡頭大量的使用四維張量運算,三維空間加一維時間。
而在做Neurel Network時,我們會根據需求不同設計不同形式但合理的流程(Flow),再使用數據來訓練我的Model。所以,這就是Tensorflow命名由來:Tensor+Flow。
因此,一開始要先設計Model的結構,這在Tensorflow裡頭稱為Graph,Graph的作用是事先決定Neurel Network的結構,決定Neuron要怎麼連接?決定哪一些窗口是可以由外部置放數據的?決定哪一些變數是可以被訓練的?哪一些變數是不可以被訓練的?定義將要怎麼樣優化這個系統?...等等。
| my_graph = tf.Graph() # Initialize a new graph
with my_graph.as_default(): # Create a scope to build graph
# ...
# detail of building graph
|
Graph只是一個結構,它不具有有效的資訊,而當我們定義完成Graph之後,接下來我們需要創造一個環境叫做Session,Session會將Graph的結構複製一份,然後再放入資訊進行Training或是預測等等,因此Session是具有有效資訊的。
| with tf.Session(graph=my_graph) as sess: # Copy graph into session
# ...
# detail of doing machine learning
|
還有另外一種寫法也是相同作用的,我個人比較喜歡下面這種寫法。
| my_session = tf.Session(graph=my_graph)
my_session.run(...)
|
Tensorflow的基本「張量」元素
接下來我們就來看看有哪些構成Graph的基本元素可以使用。
(1) 常數張量:
一開始來看看「常數張量」,常數指的是在Model中不會改變的數值。
| tensor = tf.constant([1, 2, 3, 4, 5, 6, 7], dtype=tf.int32)
|
(2) 變數張量:
與常數截然不同的就是變數,「變數張量」是指在訓練當中可以改變的值,一般「變數張量」會用作於Machine Learning需要被訓練的參數,如果你沒有特別設定,在最佳化的過程中,Tensorflow會自動調整「變數張量」的數值來最佳化。
| tensor = tf.Variable(tf.truncated_normal(shape=(3, 5)))
|
因為變數通常是未知且待優化的參數,所以我們一般會使用Initalizer來設定它的初始值,tf.truncated_normal(shape=(3,5))會隨機產生大小3x5的矩陣,它的值呈常態分佈但只取兩個標準差以內的數值。
如果今天你想要有一個「變數張量」但是又不希望它因為最佳化而改變,這時你要特別指定trainable為False。
| tensor = tf.Variable(5, trainable=False)
|
(3) 置放張量:
另外有一些張量負責擔任輸入窗口的角色,稱為Placeholder。
| tensor = tf.placeholder(tf.float32, shape=(None, 1000))
|
因為我們在訓練之前還尚未知道Data的數量,所以這裡使用None來表示未知。tf.placeholder在Graph階段是沒有數值的,必須等到Session階段才將數值給輸入進去。
(4) 操作型張量:
這類張量並不含有實際數值,而是一種操作,常用的「操作型張量」有兩種,第一種是作為最佳化使用,
| loss = ...
train_op = tf.train.GradientDescentOptimizer(learning_rate=0.5).minimize(loss)
|
選擇Optimizer和最佳化的方式來定義最佳化的操作方法,上述的例子是使用learning_rate為0.5的Gradient Descent來降低loss。
另外一種是初始化的操作,
| init_op = tf.global_variables_initializer()
|
這一個步驟是必要的但常常被忽略,還記得剛剛我們定義「變數張量」時有用到Initalizer,這些Initalizer在Graph完成時還不具有數值,必須使用init_op來給予數值,所以記住一定要放init_op進去Graph裡頭,而且必須先定義完成所有會用到的Initalizer再來設定這個init_op。
Session的操作
「張量」元素具有兩個面向:功能和數值,在Graph階段「張量」只具有功能但不具有數值,只有到了Session階段才開始有數值,那如何將這些數值取出來呢?有兩種方法,以1+1當作範例來看看,
| g1 = tf.Graph()
with g1.as_default():
x = tf.constant(1)
y = tf.constant(1)
sol = tf.add(x,y) # add x and y
with tf.Session(graph=g1) as sess:
print(sol) # print tensor, not their value
|
| Tensor("Add:0", shape=(), dtype=int32)
|
| with tf.Session(graph=g1) as sess:
print(sol.eval()) # evaluate their value
|
| s1 = tf.Session(graph=g1)
print(s1.run(sol)) # another way of evaluating value
|
那如果我想使用placeholder來做到x+y呢?
| g2 = tf.Graph()
with g2.as_default():
x = tf.placeholder(tf.int32)
y = tf.placeholder(tf.int32)
sol = tf.add(x,y) # add x and y
s2 = tf.Session(graph=g2)
# if x = 2 and y = 3
print(s2.run(sol, feed_dict={x: 2, y: 3}))
|
| # if x = 5 and y = 7
print(s2.run(sol, feed_dict={x: 5, y: 7}))
|
因為x和y是placeholder,所以必須使用feed_dict來餵入相關資訊,否則會報錯。
第一個Tensorflow Model
有了以上的認識我們就可以來建立我們第一個Model。
以下我會使用物件導向的寫法,讓程式碼更有條理。
Machine Learning在操作上可以整理成三個大步驟:建構(Building)、訓練(Fitting)和推論(Inference),所以我們將會使用這三大步驟來建製我們的Model。
在SimpleLogisticClassification裡頭,「建構」的動作在__init__中會進行,由build函式來建立Graph,其中我將Neurel Network的結構分離存於structure裡。「訓練」的動作在fit中進行,這裡採用傳統的Gradient Descent的方法,將所有Data全部考慮進去最佳化,未來會再介紹Batch Gradient Descent。最後,「推論」的部分在predict和evaluate中進行。
SimpleLogisticClassification將會建構一個只有一層的Neurel Network,也就是說沒有Hidden Layer,畫個圖。
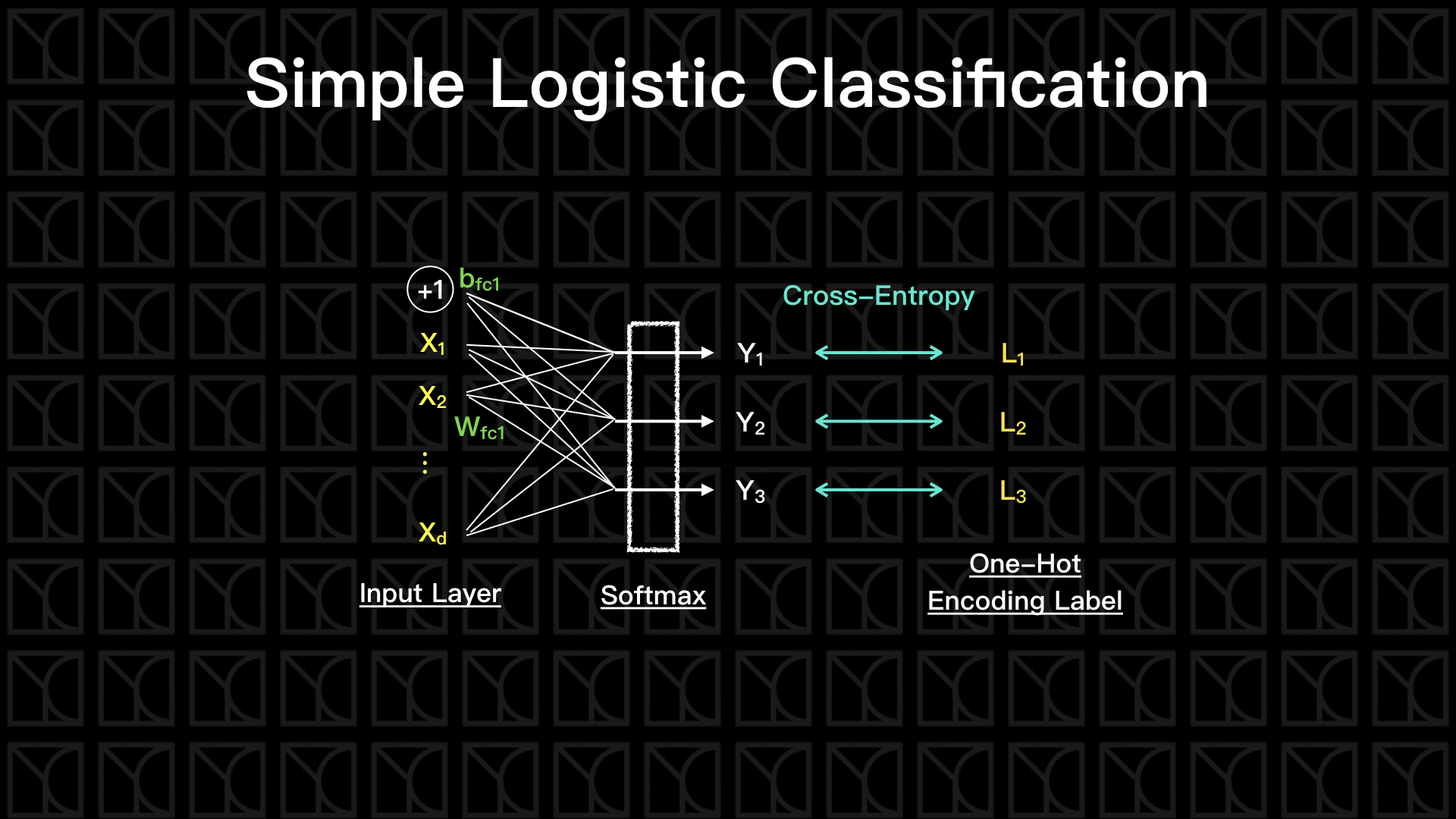
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113 | class SimpleLogisticClassification:
def __init__(self, n_features, n_labels, learning_rate=0.5):
self.n_features = n_features
self.n_labels = n_labels
self.weights = None
self.biases = None
self.graph = tf.Graph() # initialize new graph
self.build(learning_rate) # building graph
self.sess = tf.Session(graph=self.graph) # create session by the graph
def build(self, learning_rate):
# Building Graph
with self.graph.as_default():
### Input
self.train_features = tf.placeholder(tf.float32, shape=(None, self.n_features))
self.train_labels = tf.placeholder(tf.int32, shape=(None, self.n_labels))
### Optimalization
# build neurel network structure and get their predictions and loss
self.y_, self.loss = self.structure(features=self.train_features,
labels=self.train_labels)
# define training operation
self.train_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(self.loss)
### Prediction
self.new_features = tf.placeholder(tf.float32, shape=(None, self.n_features))
self.new_labels = tf.placeholder(tf.int32, shape=(None, self.n_labels))
self.new_y_, self.new_loss = self.structure(features=self.new_features,
labels=self.new_labels)
### Initialization
self.init_op = tf.global_variables_initializer()
def structure(self, features, labels):
# build neurel network structure and return their predictions and loss
### Variable
if (not self.weights) or (not self.biases):
self.weights = {
'fc1': tf.Variable(tf.truncated_normal(shape=(self.n_features, self.n_labels))),
}
self.biases = {
'fc1': tf.Variable(tf.zeros(shape=(self.n_labels))),
}
### Structure
# one fully connected layer
logits = self.get_dense_layer(features, self.weights['fc1'], self.biases['fc1'])
# predictions
y_ = tf.nn.softmax(logits)
# loss: softmax cross entropy
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits))
return (y_, loss)
def get_dense_layer(self, input_layer, weight, bias, activation=None):
# fully connected layer
x = tf.add(tf.matmul(input_layer, weight), bias)
if activation:
x = activation(x)
return x
def fit(self, X, y, epochs=10, validation_data=None, test_data=None):
X = self._check_array(X)
y = self._check_array(y)
self.sess.run(self.init_op)
for epoch in range(epochs):
print('Epoch %2d/%2d: ' % (epoch+1, epochs))
# fully gradient descent
feed_dict = {self.train_features: X, self.train_labels: y}
self.sess.run(self.train_op, feed_dict=feed_dict)
# evaluate at the end of this epoch
y_ = self.predict(X)
train_loss = self.evaluate(X, y)
train_acc = self.accuracy(y_, y)
msg = ' loss = %8.4f, acc = %3.2f%%' % (train_loss, train_acc*100)
if validation_data:
val_loss = self.evaluate(validation_data[0], validation_data[1])
val_acc = self.accuracy(self.predict(validation_data[0]), validation_data[1])
msg += ', val_loss = %8.4f, val_acc = %3.2f%%' % (val_loss, val_acc*100)
print(msg)
if test_data:
test_acc = self.accuracy(self.predict(test_data[0]), test_data[1])
print('test_acc = %3.2f%%' % (test_acc*100))
def accuracy(self, predictions, labels):
return (np.sum(np.argmax(predictions, 1) == np.argmax(labels, 1))/predictions.shape[0])
def predict(self, X):
X = self._check_array(X)
return self.sess.run(self.new_y_, feed_dict={self.new_features: X})
def evaluate(self, X, y):
X = self._check_array(X)
y = self._check_array(y)
return self.sess.run(self.new_loss, feed_dict={self.new_features: X, self.new_labels: y})
def _check_array(self, ndarray):
ndarray = np.array(ndarray)
if len(ndarray.shape) == 1:
ndarray = np.reshape(ndarray, (1, ndarray.shape[0]))
return ndarray
|
| model = SimpleLogisticClassification(n_features=28*28, n_labels=10, learning_rate= 0.5)
model.fit(
X=train_data.images,
y=train_data.labels,
epochs=10,
validation_data=(valid_data.images, valid_data.labels),
test_data=(test_data.images, test_data.labels),
)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 | Epoch 1/10:
loss = 9.2515, acc = 12.81%, val_loss = 9.4888, val_acc = 11.92%
Epoch 2/10:
loss = 8.2946, acc = 13.89%, val_loss = 8.5156, val_acc = 13.10%
Epoch 3/10:
loss = 7.5609, acc = 15.92%, val_loss = 7.7680, val_acc = 15.02%
Epoch 4/10:
loss = 6.9563, acc = 18.31%, val_loss = 7.1521, val_acc = 17.44%
Epoch 5/10:
loss = 6.4402, acc = 20.94%, val_loss = 6.6249, val_acc = 19.80%
Epoch 6/10:
loss = 5.9915, acc = 23.35%, val_loss = 6.1650, val_acc = 22.38%
Epoch 7/10:
loss = 5.5971, acc = 25.79%, val_loss = 5.7596, val_acc = 24.98%
Epoch 8/10:
loss = 5.2479, acc = 28.18%, val_loss = 5.4001, val_acc = 27.30%
Epoch 9/10:
loss = 4.9376, acc = 30.46%, val_loss = 5.0803, val_acc = 29.86%
Epoch 10/10:
loss = 4.6608, acc = 32.71%, val_loss = 4.7947, val_acc = 32.20%
test_acc = 33.58%
|