實作Tensorflow (6):Recurrent Neural Networks (RNN) and Long Short-Term Memory (LSTM)
Posted on November 25, 2017 in AI.ML. View: 12,934
如果我們想要處理的問題是具有時序性的,該怎麼辦呢?本章將會介紹有時序性的Neurel Network。
本單元程式碼LSTM部分可於Github下載。
概論RNN
當我們想使得Neurel Network具有時序性,我們的Neurel Network就必須有記憶的功能,然後在我不斷的輸入新資訊時,也能同時保有歷史資訊的影響,最簡單的作法就是將Output的結果保留,等到新資訊進來時,將新的資訊和舊的Output一起考量來訓練Neurel Network。
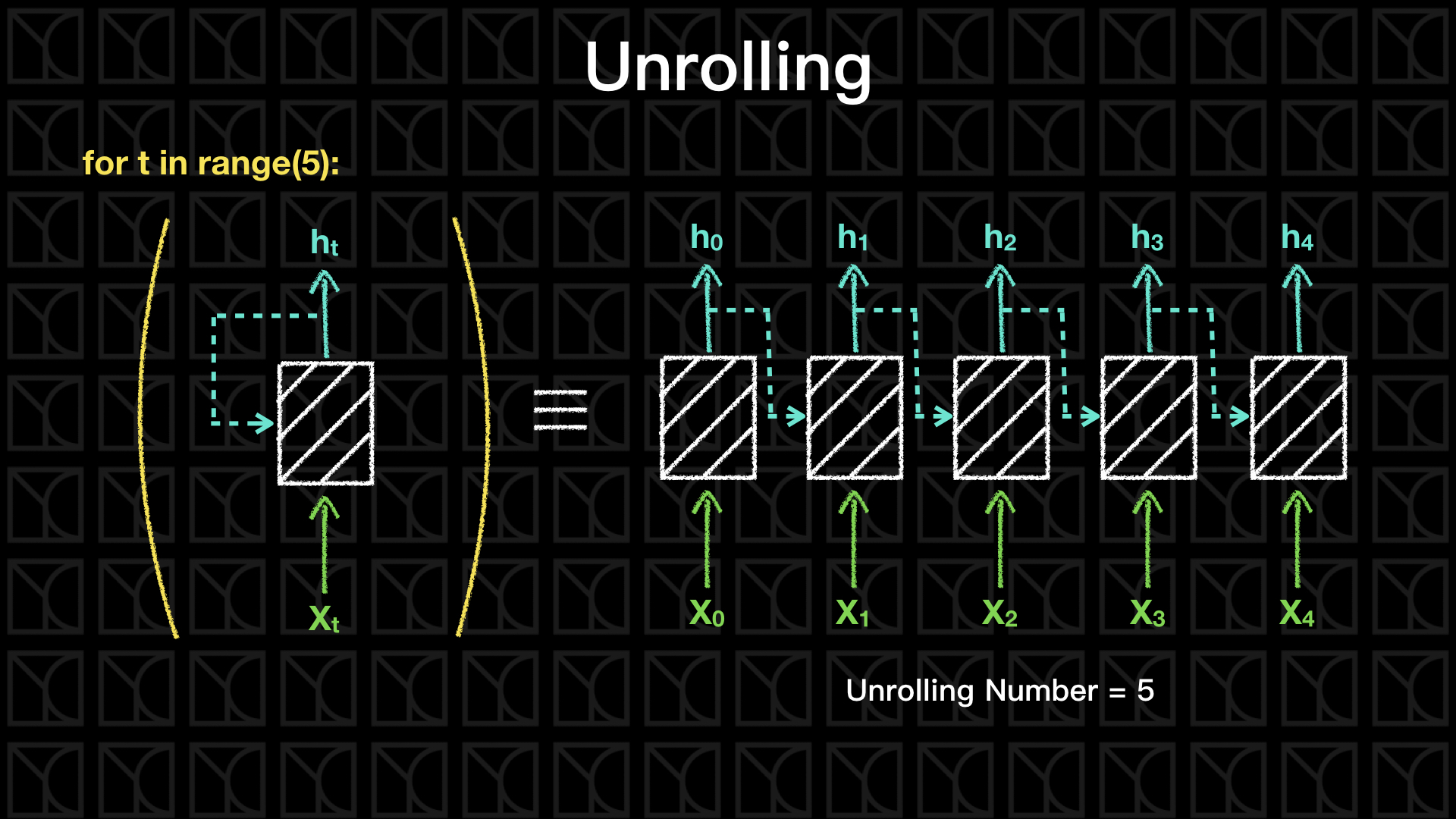
這種將舊有資訊保留的Neurel Network統稱為Recurrent Neural Networks (RNN),這種不斷回饋的網路可以攤開來處理,如上圖,如果我有5筆數據,拿訓練一個RNN 5個回合並做了5次更新,其實就等效於攤開來一次處理5筆數據並做1次更新,這樣的手法叫做Unrolling,我們實作上會使用Unrolling的手法來增加計算效率。
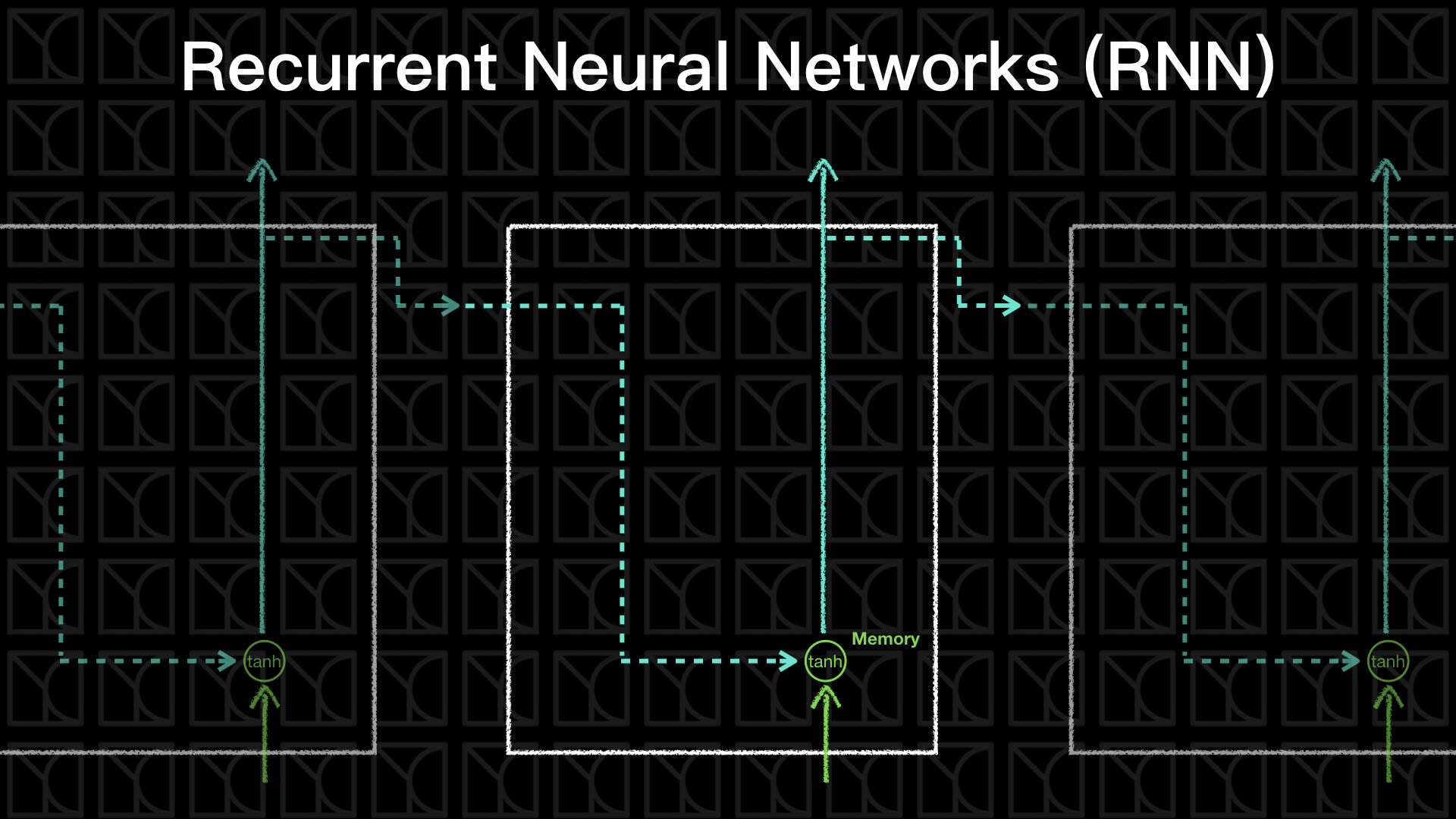
接下來來看RNN內部怎麼實現的,上圖是最簡單的RNN形式,我們將上一回產生的Output和這一回的Input一起評估出這一回的Output,詳細式子如下:
如此一來RNN就具有時序性了,舊的歷史資料將可以被「記憶」起來,你可以把RNN的「記憶」看成是「短期記憶」,因為它只會記得上一回的Output而已。
梯度消失與梯度爆炸
但這種形式的RNN在實作上會遇到很大的問題,還記得第二章當中,我們有講過像是tanh這類有飽和區的函數,會造成梯度消失的問題,而我們如果使用Unrolling的觀點來看RNN,將會發現這是一個超級深的網路,Backpapagation必須一路通到t0的RNN,想當然爾,有些梯度將會消失,部分權重就更新不到了,那有一些聰明的讀者一定會想到,那就使用Relu就好啦!不過其實還有一個重要的因素造成梯度消失,同時也造成梯度爆炸。
注意喔!雖然我們使用Unrolling的觀點,把網路看成是一個Deep網路的連接,但是和之前DNN不同之處,這些RNN彼此間是共享同一組權重的,這會造成梯度消失和梯度爆炸兩個問題,在RNN的結構裡頭,一個權重會隨著時間不斷的加強影響一個單一特徵,因為不同時間之下的RNN Cell共用同一個權重,這麼一來若是權重大於1,影響將會隨時間放大到梯度爆炸,若是權重小於1,影響將會隨時間縮小到梯度消失,就像是蝴蝶效應一般,微小的差異因為回饋的機制,而不合理的放大或是消失,因此RNN的Error Surface將會崎嶇不平,這會造成我們無法穩定的找到最佳解,難以收斂。這才是RNN難以使用的重要原因,把Activation Function換成Relu不會解決問題,文獻上反而告訴我們會變更差。
解決梯度爆炸有一個聽起來很廢但廣為人們使用的方法,叫做Gradient Clipping,也就是只要在更新過程梯度超過一個值,我就切掉讓梯度維持在這個上限,這樣就不會爆炸啦,待會會講到的LSTM只能夠解決梯度消失問題,但不能解決梯度爆炸問題,因此我們還是需要Gradient Clipping方法的幫忙。
在Tensorflow怎麼做到Gradient Clipping呢?作法是這樣的,以往我們使用optimizer.minimize(loss)來進行更新,事實上我們可以把這一步驟拆成兩部分,第一部分計算所有參數的梯度,第二部分使用這些梯度進行更新。因此我們可以從中作梗,把gradients偷天換日一番,一開始使用optimizer.compute_gradients(loss)來計算出個別的梯度,然後使用tf.clip_by_global_norm(gradients, clip_norm)來切梯度,最後再使用optimizer.apply_gradients把新的梯度餵入進行更新。
Long Short-Term Memory (LSTM)
LSTM是現今RNN的主流,它可以解決梯度消失的問題,我們先來看看結構,先預告一下,LSTM是迄今為止這系列課程當中看過最複雜的Neurel Network。
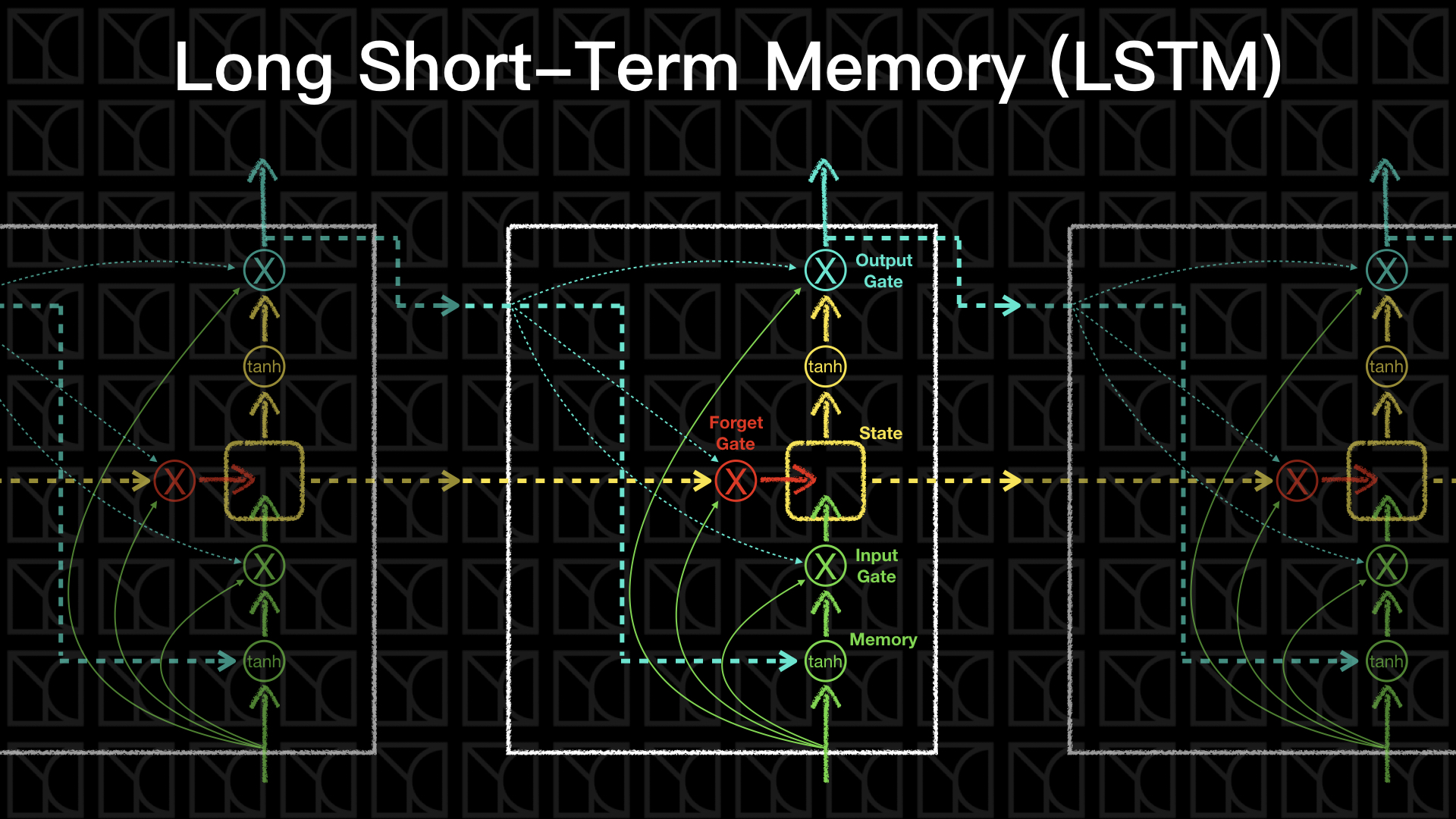
最一開始和RNN一樣,Input會和上一回的Output一起評估一個「短期記憶」,
但接下來不同於RNN直接輸出,LSTM做了一個類似於轉換成「長期記憶」的機制,「長期記憶」在這裡稱為State,State的狀態由三道門所控制,Input Gate負責控管哪些「短期記憶」可以進到「長期記憶」,Forget Gate負責調配哪一些「長期記憶」需要被遺忘,Output Gate則負責去決定需要從「長期記憶」中輸出怎樣的內容,先不要管這些Gate怎麼來,我們可以把這樣的記憶機制寫成以下的式子,假設State為\(f_{state}\)、Input Gate為\(G_i\)、Forget Gate為\(G_f\)和Output Gate為\(G_o\)。
如果我們要使得上面中Gates的部分具有開關的功能的話,我們會希望Gates可以是0到1的值,0代表全關,1代表全開,sigmoid正可以幫我們做到這件事,那哪些因素會決定Gates的關閉與否呢?不妨考慮所有可能的因素,也就是所有輸入這個Cell的資訊都考慮進去,但上一回的State必須被剔除於外,因為上一回的State來決定下一個State的操作是不合理的,因此我們就可以寫下所有Gates的表示式了。
這就是LSTM,「長期記憶」的出現可以解決掉梯度消失的問題,RNN只有「短期記憶」,所以一旦認為一個特徵不重要,經過幾回連乘,這個特徵的梯度就會消失殆盡,但是LSTM保留State,並且使用「加」的方法更新State,所以有一些重要的State得以留下來持續影響著Output,解決了梯度消失的問題。但是,不幸的LSTM還是免不了梯度爆炸,為什麼呢?如果一個特徵真的很重要,State會記住,Input也會強調,所以幾輪下來還是有可能出現爆炸的情況,這時候我們就需要Gradient Clipping的幫忙。
使用LSTM實作文章產生器
接下來我們來實作LSTM,目標是做一個文章產生器,我們希望機器可以不斷的根據前文猜測下一個「字母」(Letters)應該要下什麼,如此一來我只要給個開頭字母,LSTM就可以幫我腦補成一篇文章。
1 2 3 4 5 6 7 8 9 10 11 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | |
1 2 3 4 5 6 7 8 9 | |
上面操作我們建制完成了字母庫,接下來就可以產生我們訓練所需要的Batch Data,所以我們來看看究竟要產生怎樣格式的資料。
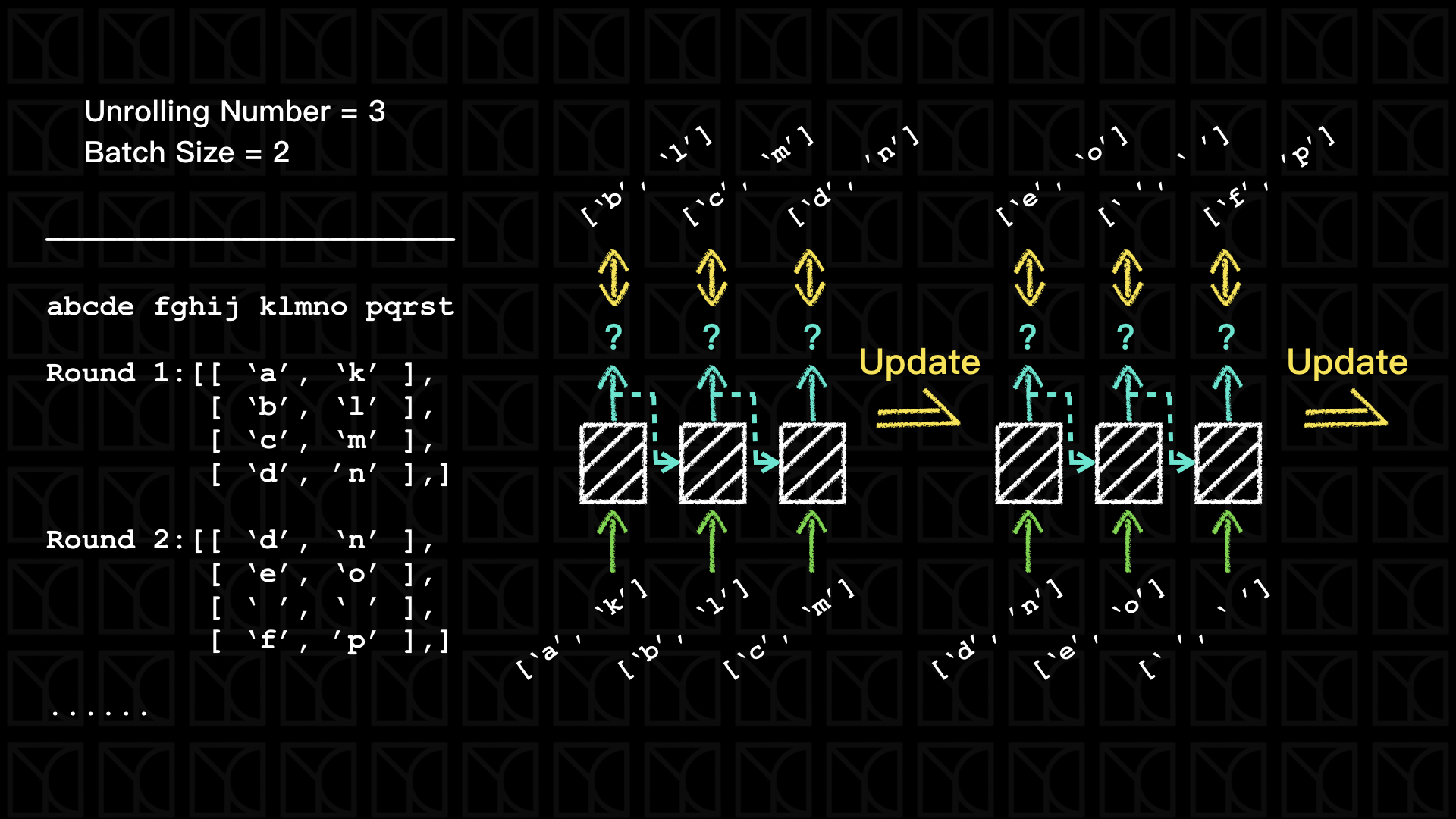
如上圖所示,有點小複雜,假設我要設計一個LSTM Model,它的Unrolling Number為3,Batch Size為2,然後遇到的字串是"abcde fghij klmno pqrst",接下來就開始產生每個Round要用的Data,產生的結果如上圖所示,你會發現產生的Data第0軸表示的是考慮unrolling需要取樣的資料,總共應該會有(Unrolling Number+1)筆,如上圖例,共有4筆,3筆當作輸入而3筆當作Labels,中間有2筆重疊使用,另外還有一點,我們會保留最後一筆Data當作下一個回合的第一筆,這是為了不浪費使用每一個字母前後的組合。而第1軸則是餵入單一LSTM需要的資料,我們一次可以餵多組不相干的字母進去,如上圖例,Batch Size=2所以餵2個字母進去,那這些不相干的字母在取樣的時候,我們會盡量讓它平均分配在文字庫,才能確保彼此之間不相干,以增加LSTM的訓練效率和效果。
因此,先產生Batch Data吧!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | |
1 2 3 4 5 6 | |
定義一下待會會用到的函數。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
開始建制LSTM Model。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 | |
最後來產生一篇以"t"為開頭的1000字文章吧!
1 | |
1 | |
看得出來LSTM想表達什麼嗎,哈哈!