物件導向武功秘笈(3):內功篇 — 物件導向指導原則SOLID
Posted on April 14, 2018 in CS. View: 9,510
物件導向怎麼用才能成就好的程式碼?
一個好的工具,也要配合對於工具的理解,才能發揮效用。在上一回中,我們完整介紹了Java和Python的物件導向實現方式,我們講到了「封裝」、「繼承」、「多型」等等物件導向的特色,也講了「抽象類別」、「接口」等抽象化的方法,不過我並沒有告訴大家該怎麼用這些工具?使用這些工具是不是有什麼樣的法則?
在接下來的這一篇,我將會介紹物件導向的使用方式,我會提到物件導向著名的六大法則SOLID:
- 單一職責原理
- 開閉原理
- 里氏替換原則
- 迪米特法則
- 依賴倒置原則
- 接口分隔原則
在這之前我們先來介紹描述類別關係的UML類別圖。
UML類別圖
開始介紹各種原則之前,先來介紹UML類別圖,UML全名稱為Unified Modeling Language,是一種使用圖形來描繪軟體工程架構的方法,這邊準備介紹的是它的類別圖,這個工具有助於我們快速的了解物件與物件之間的關係。
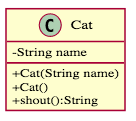
首先先來看一下UML類別圖的節點,共有三種:
- 類別(Class): 其中第一個 block 表示名稱、第二個 block 表示變數、第三個 block 表示方法。而
-代表private,+代表public,#代表protected
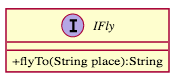
- 抽象類別(Abstract Class)

- 接口(Interface)
接下來來了解UML類別圖的連接關係,從連接關係的強到弱依序介紹:
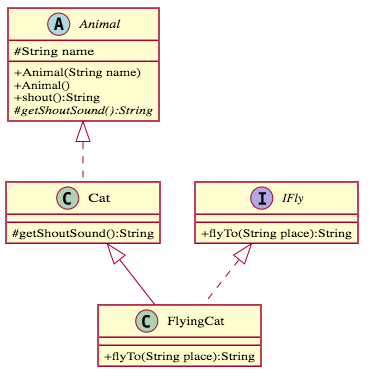
- 繼承關係(Inheritance)和抽象類、接口實現:在UML類別圖中,箭頭方向代表依賴方向,A箭頭指向B,代表A依賴B,代表B的改變將連同改變A,而A的改變不影響B。因此在繼承關係中,子類箭頭指向父類,意味著子類依賴父類。
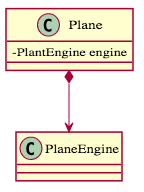
- 合成(組合)關係(Composition):指的是 "is-part-of" 的關係,是一個強的「擁有」關係。實心菱形指向整體、箭頭指向部件(代表整體依賴部件),整體不可以脫離部件而存在,例如下面範例中飛機不能沒有引擎。在程式碼中,通常部件會放在「成員變數」中,並且在實例化時就產生。
1 2 3 4 5 6 7 | |
- 聚合關係(Aggregation):指的是 "owns-a" 的關係,是一個弱的「擁有」關係。空心菱形指向整體、箭頭指向部件(代表整體依賴部件),整體可以脫離部件而存在,整體和部件擁有各自的生命週期,例如下面範例中飛機場有停放飛機,但是除去飛機,飛機場仍可以正常運作。在程式碼中,通常部件會放在「成員變數」中。
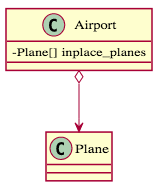
1 2 3 4 5 6 7 | |
- 關聯關係(Association):指的是 "has-a" 的關係,是個「有個」的關係。兩種類別擁有各自的生命週期,且兩者並不具備整體與部件的關係,我們使用 Association 來連接,箭頭代表依賴的方向,例如下面範例中飛機和排程不具有整體與部件的關係,但飛機有個排程。在程式碼中,會放在「成員變數」中。
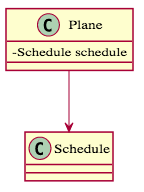
1 2 3 4 5 6 7 | |
- 依賴關係(Dependency):指的是 "uses-a" 的關係,是個「使用」的關係。A類中使用到B類,但僅僅是弱連結(在程式碼中,不放在「成員變數」中),譬如:B類作為A類方法的參數、B類作為A類的局域變數、A類調用B類的靜態方法、B類作為A類方法的回傳值,就稱為:A依賴B。
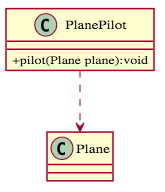
1 2 3 4 5 6 7 | |
單一職責原則(Single Responsibility Principle, SRP)
-
定義:There should never be more than one reason for a class to change.(一個類別中不要有多於一個以上的變化理由)
-
簡單的說,就是一個類別中不要做超過一件事,要去切分直到不能再分割為止,如此一來可以提高內聚性。
-
乍看之下,這樣的原則很容易實現,但是魔鬼藏在細節裡,我們常常會沒注意到其實還可以繼續的切分。舉個例子,假設我想設計一個電話的接口,我可能是這樣設計的
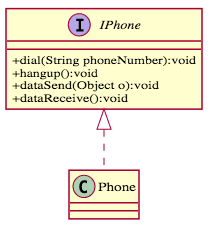
乍看之下沒有問題,一個電話擁有撥號、掛號、數據傳送和接收,但是等等!連接的過程和數據的傳輸其實是兩個職責啊!它們之間沒有強烈的關聯性,完全是可以分開處理的,因此這個配置不符合「單一職責原則」,可以繼續切分下去,修改如下。
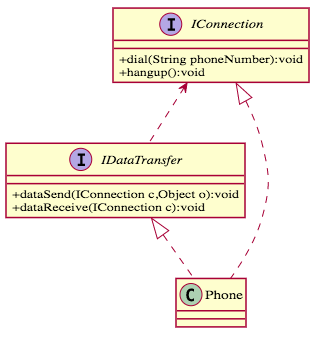
- 「單一職責原則」原文指的是類別的單一職責,但是務實上,類別如果切分到如此程度,程式碼會變得細碎不堪,這違反了程式碼的「可讀性」,所以我們一般只要求「接口必須保持單一原則」,而類別去套用接口,類別就盡量達成少的職責就好。
開閉原則(Open-Closed Principle, OCP)
-
定義:Software entities (classes, modules, functions, etc.) should be open for extension, but closed for modification.(軟體中的實體,例如:類、模組、函數等等,都必須對延伸開放,但對修改封閉)
-
對延伸開放:實體在因應新的改變時,必須是可以靈活擴充的。
-
對修改封閉:實體一旦完成,就盡量不要再去修改它了。
-
綜合以上兩點,我們可以總結出:實體本身的內聚性要高,可以讓我們未來不需要再做修改,單一職責可以做到增強內聚性;實體間的耦合性要低,所以實體像是積木一樣可以因應各種需求去任意組合、擴充。所以「開閉原則」只是進一步的把「低耦合高內聚」再說的更清楚一點,實現「開閉原則」將有利於單元測試、提高維護和擴充能力。
里氏替換原則(Liskov Subsititution Principle, LSP)
-
定義:What is wanted here is something like the following substitution property: If for each object o1 of type S there is an object o2 of type T such that for all programs P defined in terms of T, the behavior of P is unchanged when o1 is substituted for o2 then S is a subtype of T.(簡言之:子類對象能夠替換其父類對象,使用父類方法而不會有問題)
-
「里氏替換原則」用於規範繼承,子類繼承自父類的方法是保有彈性可以覆寫(Overriding)和多載(Overloading)的,但是應該怎麼做,程式碼才不會髒掉?「里氏替換原則」告訴我們一個簡單的法則,就是先寫一段父類的執行代碼,然後把父類替換成子類,然後再跑跑看能不能正常執行,如果正常執行代表這個繼承關係是健康的。
-
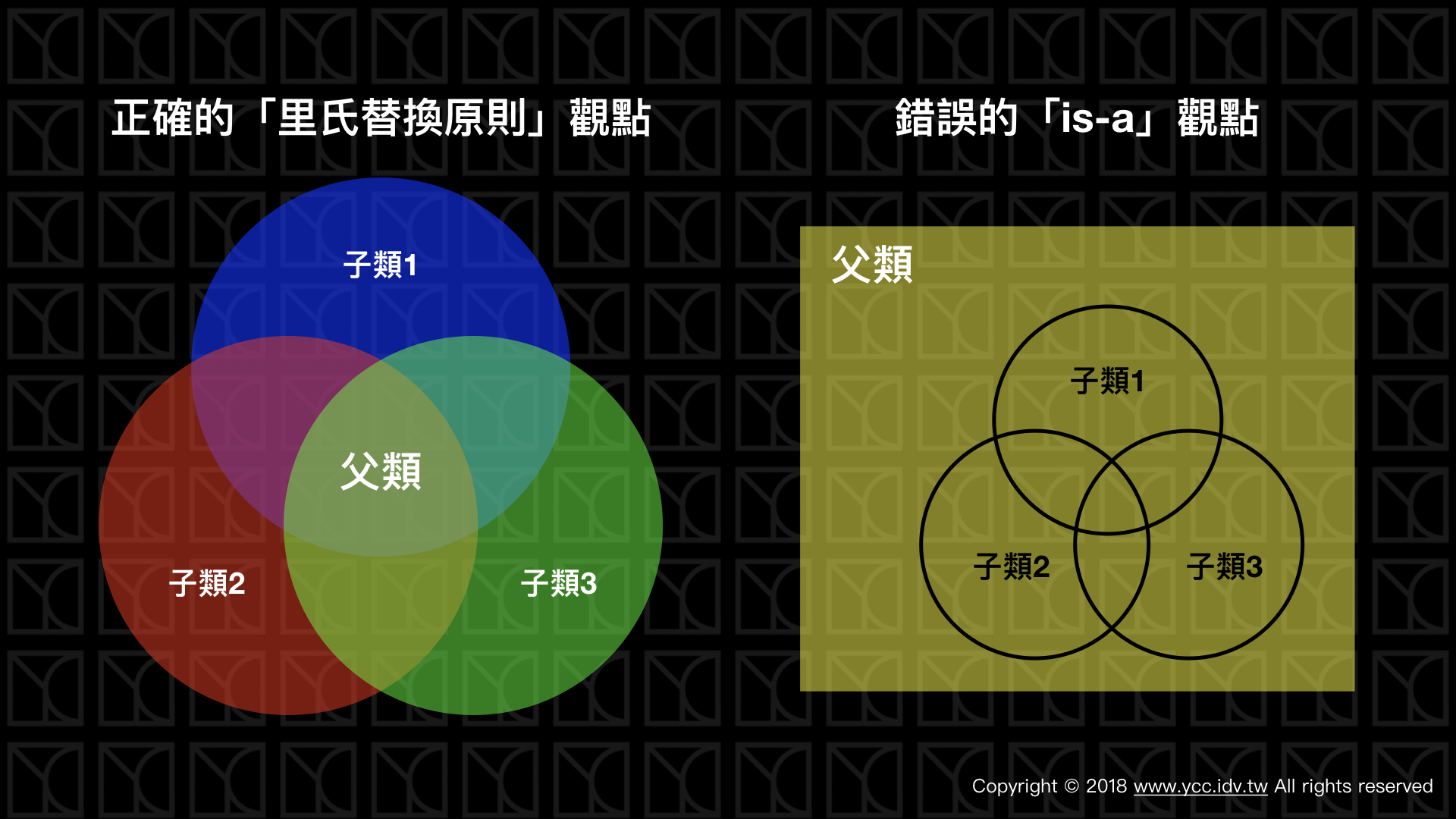
為什麼要這樣檢查?之前我們提過繼承主要是為了要避免Repeat Yourself而生,我們找出各種類別共享的屬性和方法,把它獨立出來,然後大家再一起繼承自它,所以我們要盡可能的避免父類出現不是共享的性質。也就是說在理想情況下「父類必須等於子類們的交集」,所以「父類必定是任一子類的子集合」,因此「使用子類來執行父類是不應該有問題的」,這就是「里氏替換原則」。
-
為了遵循「里氏替換原則」,則子類必須完全實現父類的方法。如果子類不能完整地實現父類的方法,或者父類的某些方法在子類中已經發生了「畸變」,則建議斷開父子繼承關係,採用依賴、聚集、組合等關係替代。
-
有了「里氏替換原則」,我們終於可以談談一個上一章沒提到的重要問題:什麼情況可以做繼承?有一些書籍會告訴你,繼承為"is-a"的關係,例如:瑪爾濟斯(B) is-a 狗(A),所以瑪爾濟斯(B)可以繼承狗(A),乍看之下沒問題,但這樣的說法存在缺陷,舉個例子,假設今天我先有了類別
Retangle,也就是長方形,然後我想要弄一個新的類別Square,也就是正方形,我可以讓Square繼承自Retangle嗎?我們用"is-a"來檢視:正方形是一個長方形?答案是Yes,但是「里氏替換原則」持相反意見,來看一下,
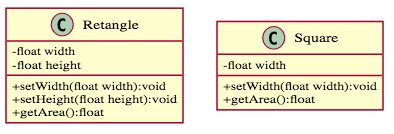
依照「里氏替換原則」,Square不能繼承自Retangle,因為Square只需要width的成員變數,而Retangle則需要width和height兩個成員變數,當我們將子類Square放到父類Retangle的方法中,因為缺少height變數,必然會出錯,所以違反「里氏替換原則」,因此這兩類不適合作為「繼承」關係。我們可以這樣改善,讓Square應用Retangle來幫忙計算,使用「關聯」關係取代「繼承」關係。
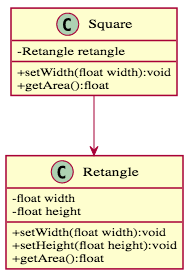
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
- 下面這一張集合圖是我自創的,圖中清楚的指出「繼承」中的父類和子類應該是什麼樣的關係。
迪米特法則(Law of Demeter, LoD)
又稱為「最少知識原則」,它規定物件應該要對其他物件有最少的了解。
規則1:一個物件應該與它「朋友」互動,而不應該與陌生對象互動。這樣可以減少耦合,提高物件之間的低耦合性,使得物件與物件之間的關係更加簡單易懂。「朋友」的定義:對於類別 C 的其中一個方法 M 而言,在 M 的方法中僅能訪問以下物件:
self,類別 C 自身- C 的成員變數
- M 的輸入參數
- M 的輸出物件
- 全域變數的物件
舉個例子:假設今天一名老師給了學生名條想叫班長幫忙點名
錯誤示範:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
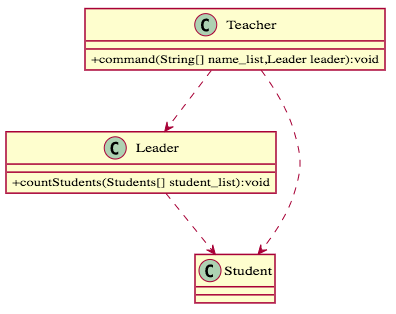
我們來使用「迪米特法則」來檢驗一下,Teacher.command 的「朋友」有 self、輸入參數 name_list (List[String]) 和 leader (Leader),但在上面這個例子它使用到了不是「朋友」的 Student,這會使得 Teacher 和 Student 會產生不必要的耦合。解法是,我們可以將創造 student_list 的權責轉移到 Leader 上,如此一來就可以斷開 Teacher 和 Student 的耦合。
正確示範:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
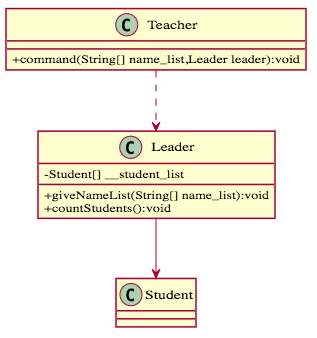
為什麼這樣規範呢?先來想想「朋友」有什麼共通之處,其實它們都是類別本身無法斷開耦合的物件,既然無法斷開耦合,何不運用到底,運用這些「朋友」來完成任務,不要再去增加其他的耦合性,也同時幫助提升類別的內聚性,這就是「迪米特法則」想做的事。以這樣的方式去寫程式,也可以避免寫出像是A.getB().getC()的程式碼(A和C不是朋友),這樣冗長的程式碼不僅增加了無益的耦合,也讓程式變得不利於可讀性。
規則2:減少類別的對外方法,將沒必要對外公布的方法隱藏起來。
例子: 安裝程式。
錯誤範例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
有太多沒必要對外公布的細節了,依照「迪米特法則」,我們應該將盡量減少對外公布的資訊,把不必要公布的細節私有化。
正確範例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
依賴倒置原則(Dependence Inversion Principle, DIP)
- 定義:High level modules should not depend upon low level modules. Both should depend upon abstractions. Abstractions should not depend upon details. Details should depend upon abstractions.(高階模組不應該依賴低階模組,兩者都應該依賴抽象。而抽象不應該依賴細節,反之細節應該要依賴抽象。)
- 它要求高階模組不應該依賴低階模組,而是應該依賴抽象。這意味著在設計類之間的關係時,應該避免直接依賴具體類,而是應該依賴抽象類。這樣可以使得高階模組不受低階模組的影響,並且可以更容易地更換和修改低階模組。依賴倒置原則可以通過使用介面和抽象類來實現。
- 舉個例子,假設我們有一個高階模組,它負責讀取和顯示數據。我們有一個低階模組,它負責從文件中讀取數據。如果高階模組直接依賴低階模組,那麼如果低階模組的實現發生變化,高階模組也必須作出相應的修改。這樣不符合依賴倒置原則,我們應該抽象出一個抽象類,讓高階模組依賴於這個抽象類,而低階模組實現這個抽象類。
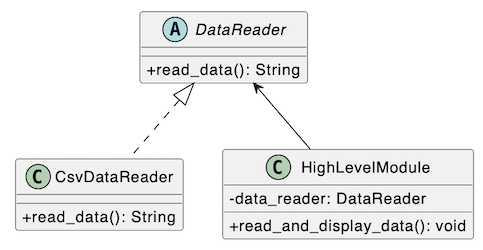
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
在上面程式碼中,DataReader是一個抽象類,它定義了一個read_data()方法。CsvDataReader是一個具體類,它實現了DataReader並從文件中讀取數據。HighLevelModule是一個高階模組,它依賴於DataReader接口而不是具體類。這樣,當低階模組的實現發生變化時,高階模組不需要作出任何修改,只需要更換實現了DataReader抽象類的具體類即可。這樣可以使得高階模組更穩定,並且可以更容易地更換和修改低階模組。同時,由於高階模組依賴的是抽象類,而不是具體類,我們可以更輕鬆地對高階模組進行測試,因為我們可以使用模擬數據來模擬低階模組的行為。
- 依賴倒置原則又稱為「面向接口原則」,這裡的接口應該想的更廣義一點,不侷限在interface上,我認為只要藉由抽象化將架構擬定出來的這些抽象單元都可以稱作接口,「廣義的接口」可以是指:
- 客戶端和業務邏輯的分離介面
- 物件的開放方法
- 抽象類別
- 定義行為的interface
接口分隔原則(Interface Segregation Principle, ISP)
- 定義:Clients should not be forced to depend uponn interfaces that they don't use. The dependency of one class to another one should depend on the smallest possible interface.(客戶類不應該被強迫依賴那些它不需要的接口,類別間的彼此依賴應該建立在盡可能小的接口上)
- 這裡說的接口同樣的是剛剛所說的「廣義接口」,可以是客戶端和業務邏輯的分離介面、物件的開放方法、抽象類別和Interface。
- 它要求將較大的接口分解成較小的接口,以適應客戶端需求。這樣做可以避免客戶端被迫使實現未使用的方法,並減少程序的耦合性。接口分隔原則建議我們要讓這些廣義接口盡可能的細切,但在實務上,切的過細會導致程式碼非常零碎難以閱讀,所以YC的建議是切到遵守「單一職責原理」就足夠了。
- 舉個例子:錯誤範例如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
上述程式碼中,SimpleDocument 類可能只需要繼承中的一部分方法,這樣的設計違反了 ISP 原則,客戶端 (SimpleDocument 和 ComplexDocument 類) 被迫使實現未使用的方法。更好的設計方法是將這些方法分為兩個不同的接口,例如 DocumentHandler 和 DocumentEncoder,並讓客戶端只實現需要的接口。修改如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
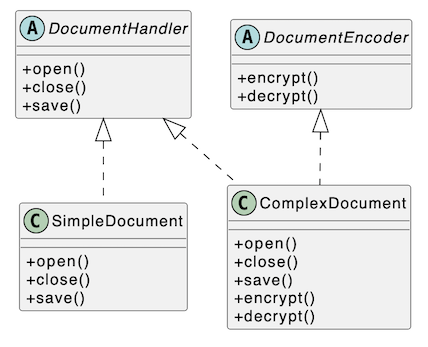
這樣的設計更符合 ISP 原則,因為客戶端 (SimpleDocument 和 ComplexDocument 類) 只實現了需要的接口,並沒有被迫使實現未使用的方法。這樣可以減少程序的耦合性,並更容易維護和擴展。
總結:物件導向的指導原則—SOLID
上面介紹的六大原理:
- Single Responsibility Principl
- Open-Closed Principle
- Liskov Subsititution Principle
- Law of Demeter
- Interface Segregation Principle
- Dependence Inversion Principle
剛剛好組成SOLID這個單字,所以又被統稱SOLID原則。
事實上,這些原則所要達到的目的,不外乎就是我們第一篇當中所介紹的好的程式碼特性:「正常執行」、「穩健」、「不重複撰寫」、「可讀性」、「可擴展」,或者是「低耦合、高內聚」,所以寫程式時如果能時時注意,說不定你也可以自己領會這六大法則。
我來快速的總結這六大法則告訴我們的事:
- 在開發程式的初期,先定義好抽象架構,也就是廣義的接口,徹底的使客戶端與業務邏輯分離,將「行為」定義成Interface,將「類別的泛化」定義成Abstract Class。
- 所有的實體類別都依賴於抽象,細節依賴於抽象。
- 每個單元盡量達到:單一權責、對延伸開放但對修改封閉、盡可能少的對外方法。
- 牽涉「繼承」,必須要問自己:子類可以替換父類執行嗎?父類是不是為子類的交集?
- 類別中的方法僅能訪問它的「朋友」們。
如此一來,我們心中就有一個準則去使用物件導向。
在一般情形下,這三篇的內容應該就足夠讓你寫出好的程式碼,但是實際面上使用仍然會碰到許多問題,於是乎有人將問題整理並總結出一些套路,這就是「設計模式」,我們以後再來談談吧!今天就先到這。